I promised a lot of folks I’d write a blog if I won the AWS AI League, so here I am writing this after finishing 2nd.

Before we begin, here’s a little brief about the competition itself, it consists of two rounds:
- You are given 72 hours to fine-tune a Llama 3.2 8B model for the given domain using AWS SageMaker JumpStart. When submitted, the fine-tuned model is evaluated against a base Llama 3.2 70B model, with an LLM as a judge, using a fixed set of 50 undisclosed questions. If your fine-tuned model’s answer is better, you get a point. Participants are ranked based on these points in the leaderboard.
- For the second round, the top 5 candidates from the first round are chosen. This time, participants craft a system prompt that their fine-tuned model (from the previous round) uses to answer the question. In this round, answers are evaluated by human judges (40%), an LLM (40%) and the audience (20%). The winner is decided based on these points after 5 questions.
Preparation
Although I have been working with LLMs for the past couple of years, prior to this event, I had only fine-tuned a model once and that too with help. So, I set out to understand it deeply before the competition and started my prep one week prior.
For starters, this video series by AWS helped me get familiar with sagemaker and model fine-tuning. I also looked at several LLM leagues of the past, stumbled upon a blog from the winner of the Singaporean AI league and the blog from first round winner from the same league. Both these blogs discuss data preparation, hyperparameter tuning, and what worked for them. I noted them all down religiously. For those unfamiliar, hyperparameters are like configuration settings that you can adjust while fine-tuning a model.
While I was familiar with data preparation, I realised that I needed to learn more about hyperparameters-that’s when I stumbled upon this blog from AWS which was a good starting point. In addition, the table at the end showing fine-tuning times for each instance-size and configuration pair was the cherry on top.

Plus, reading about these hyperparameters experiments from Finetuning LLMs with LoRA and QLoRA: Insights from Hundreds of Experiments and Practical Tips for Finetuning LLMs Using LoRA made me realise that these parameters are inherently dependent on the data, what works for one set may not necessarily work for another set but it also gave me an idea on what parameters to experiment with.
The crux of what I learnt from these articles,
- Even 1000 high quality examples is good enough to fine-tune a model
- An
epochis a hyperparameter representing one complete pass through the entire training dataset during the model training process. So, the plan was to increase epoch slowly from 1 to see which yeilds the best result. lora_r(rank) ranges from 4 to 256, with 8, 16, and 32 being common choices (determines the number of trainable parameters in the adaptation layers - high value meaning longer training time and more adaptability)lora_alphais a scaling factor that controls the magnitude of the LoRA weight updates, controls impact of adaptations and is generally kept 2x of lora_r (though above blog also notes successes with 0.5x of lora_r)- Setting lora_r or number of epoch too high can lead to overfitting
learning_raterate at which model weights are updated after working through each batch of training examples (regret not experimenting with learning rate in this competition)- Finally, enabling LoRA for more layers i.e. setting target_modules hyperparameter to
q_proj, v_proj, k_proj, o_proj, gate_proj, up_proj, down_projinstead of the defaultq_proj, v_proj. This proved very effective and almost doubled my score. This video from 3Blue1Brown will help you understand why. You can find more of these in my raw notes over here
Then, since, I had time, I thought why not automate some of these like,
- Deploying the base model
- Uploading dataset to s3
- Deploying the fine-tuned models with the given array of hyperparameters (so I didn’t have to experiment one by one)
- Evaluation against the base model or a previously fine-tuned model to check for regressions (I thought this will be faster than submitting to the leaderboard)
I even wrote scripts to increase service-quota limits for the required instances, if not already present. You can find them all here. By doing these, I thought I’ll just concentrate on preparing a good dataset on the event day.
SPOILER ALERT: None of these were useful in the competition, since we weren’t given access to a Jupyter Notebook or an AWS access key and secret key for the account. So everything had to be done manually through the AWS console.
Talking about data prepation, both these blogs discuss generating data through PartyRock. A few PartyRock apps listed below,
- QnACrafter - Used by the round 1 winner for the singaporean league
- Simple-AWS-LLMs-League-Dataset-Generator
- Advanced-AWS-LLMs-League-Dataset-Generator both by AWS
- LLMs-Datasets-Generator
I tried QnACrafter and even modified it slightly to suit my usecase for the event.
But what if synthetic data generation doesn’t work? Then I’d have to look at actual sources on the internet-but data can be in different formats like PDF, webpages or CSV
So, I looked for tools that allow us to scrape data from any available source format with minimal effort which is when I landed on synthetic-data-kit from Meta, which seems to be built exactly for this purpose, a CLI app that one can run locally to produce questions-answer pairs with PDF, csv or html as the source. It also checks for duplicates and evaluates whether each generated pair is high quality. Seemed like a perfect fit. It internally uses LLM behind the scenes to generate these datasets and allows prompt customization as well. One limitation was the lack of direct Azure OpenAI model support, since I had access to that, I added that support and built a thin wrapper to automate further; you can find the source code here.
At this point, I was clear on how to prepare data and which hyperparameters to experiment with, and all set for the competition.
Round 1 - Fine-Tuning
The exact usecase to fine-tune our model was revealed on competition day, although we had already been told that the overall domain as “SLED” (State, Local and Education)
I honestly did not know what SLED encompassed. So, I set out to find it. First I tried my modified, QnACrafter app. It auto selects different aspects when a topic is given (one can also manually specify aspects) and prepares question and answers for it, that gave me a hint but I wanted to dig deeper. Using a combination of generated aspects from PartyRock and a bit of googling, I wrote a few-shot prompt for ChatGPT to give me more SLED topics (the exact prompt below)
US State government, Local and Education - understand citizen needs in plain language.
Handle complex scenarios like "I want to open a food truck" or "My neighbor's tree fell on my property" while providing step-by-step guidance through permit applications and licensing.
Datasets generated should include realistic user queries and appropriate concise and helpful answer like an assistant from US gov public services
I am building a dataset that will help US citizens in navigation government bureaucracy
What all aspects should I cover, I have a few, listed below.
Business Licensing & Permits, Property Rights & Disputes, Education Services, Public Services & Utilities, Public Health,
Public Transport, 311 requests, building permits, health and food inspection, business registration, property and assessment,
public works and ROW permits, trees and neighbour hood issues, fire inspection and permits, benefits and human services,
education, transportation and DMV, Courts & clerks, Community legal aid guide, Street use / right‑of‑way,
Food vending & food truck, Stormwater & drainage
I want you to think about all such aspects a citizen will reach out to State and local government officals, just like I have written,
Categorize them, example,
1. Business
- (topic related to business why they would reach out, like) business licensing
- business permits
And so on, for all possible things one would likely reach outIt responded with the topic and subtopics below, exactly what I was looking for,
1. Business & Commerce
- Business formation (LLC/DBA, Secretary of State filings)
- General business license / local tax receipt
- Industry licenses (food service, salon, contractor, childcare, auto dealer)
...
2. Building, Construction & Permitting
- Building/alteration permits; plan review
- Mechanical/electrical/plumbing permits
- Occupancy and fire safety certificates
...The full set of generated topics can be found here. I generated roughly 140 topics. The idea was to feed in these topics to QnACrafter and copy the generated answers but by default it only accepts 4 aspects/topics at a time. Customizing the app to accept more resulted in partial generation, likely due to rate limiting. So, I quickly realized this is going to be time consuming and that it would be easier to write a python script instead to generate the dataset. So that’s what I did, you can find the script here.
The script uses gpt-4o and takes in a list of topics, and generates N number of questions for each topic. Each question is then passed onto another answer prompt which generates the answer. This produced my first dataset, roughly 870 odd question-answer pairs.
After the competition, many asked how I handled dataset de-duplication. I actually didn’t need a separate de-duplication step, since my approach naturally avoided it. I generated only a handful of questions per topic (about six), and a separate LLM call to generate an answer per question, there was little to no overlap.
Then, I uploaded the dataset with the base hyperparameter configuration. By this time, 5 hours had already passed, I haven’t even looked at the leaderboard yet. The model scored just 31.8%, but already put me second in the leaderboard at that time. I then, decided to perform all the hyperparameter experiments that I learnt about before discarding the dataset.
- I started by increasing epochs from 1 to 5. The evaluation percentage increased and started to decrease at 5 so I maintained the epoch at 4.
- Enabling LoRA modules for all layers (instead of just query and key) gave me the biggest jump: 86% at epoch 3 and 88% at epoch 4 with lora_r=8 and lora_alpha=16
So, the same dataset that got me 31% also fetched me 88% just by tuning the parameters, in other words my fine-tuned LLM is already answering 44/50 questions better than the 70B model.
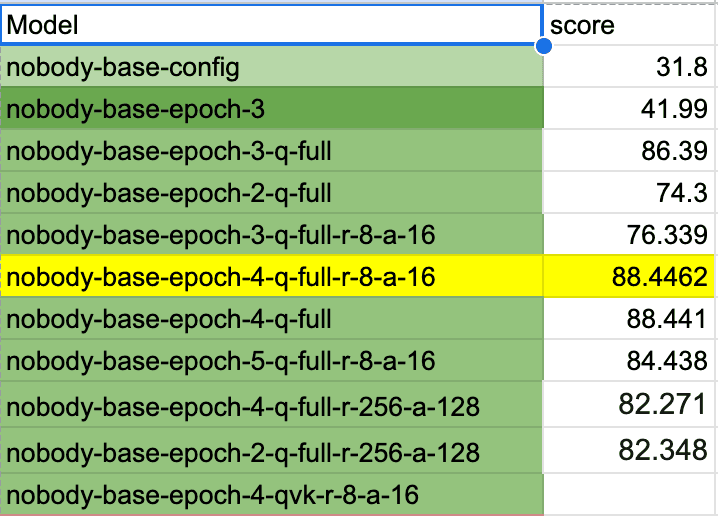
Here’s the link to the full experimentation sheet.
Another key challenge was the limited compute availability — we had access to only two ml.g5.2xlarge and one ml.g5.12xlarge instances for fine-tuning. Several of my hyperparameter configurations failed to run on the smaller instances, which meant I had to rely solely on the single 12xlarge node. This required pacing and prioritizing experiments carefully to make the most of the available resources.
After this, I tried a lot of variations with the dataset.
- If you observe my previous dataset was generic but we know laws can be different from state to state, so I generated locality-specific data. This fetched me just 15% with my best hyperparameter configuration. I understood that the evaluation is not locality specific and discarded it entirely.
- Then, I wondered if the rest of those 6 questions were in Spanish, since the U.S. has a sizable Spanish-speaking population and appended few spanish datasets for each topic. This also did not improve my score.
- Generated and appended summary-based question-answer pairs. Once again, I observed that it performed worse.
- Generated more topics with ChatGPT and used the same script to prepare more question/answer pairs for those topics. This improved my score and took me to 90%
- Any further topic generation also did not improve the scoreboard.
- I also tried switching from gpt4o to 5-mini for generating the dataset, although the questions generated by 5-mini were even more realistic for the same prompt, the score still dropped, suggesting that the evaluation set had simpler question similar to what 4o generated.
- Then, my highest score came from simply appending refusal type datasets. By refusal I mean, refusing to answer anything irrelevant or aiding harmful intent like giving away personal information of a neighbour etc. This got me upto 94%. You can find my final dataset here.
- Since this got me upto 94%, I did not use the synthetic-data-kit that I had previously tweaked
By this time, I was out of ideas to experiment with datasets but I continued experimenting with various other exotic hyperparameter configurations.
One configuration with lora_r=256 and lora alpha=128 pushed the score further, yielding just 0.001% more than my current best model but later looking at the eval/train loss metric on jumpstart I realised this model was overfitting. You can find the comparison of the parameters below.

A good rule of thumb is to keep eval loss close to training loss, which you can observe in the best model. This means the model generalizes well, otherwise it means the model is overfitting, i.e memorizing training data, such a model won’t fare well with new questions outside training data spec.
I did not check the metrics before submitting, despite knowing that a higher lora_r is likely to produce a model that overfits. Unfortunately, I couldn’t beat this model and since AWS copies the model with the highest score for the next round, this ended up being my model for the finals. (Yes, I asked if I could switch the selected model immediately after the Round 1; organizers said they couldn’t)
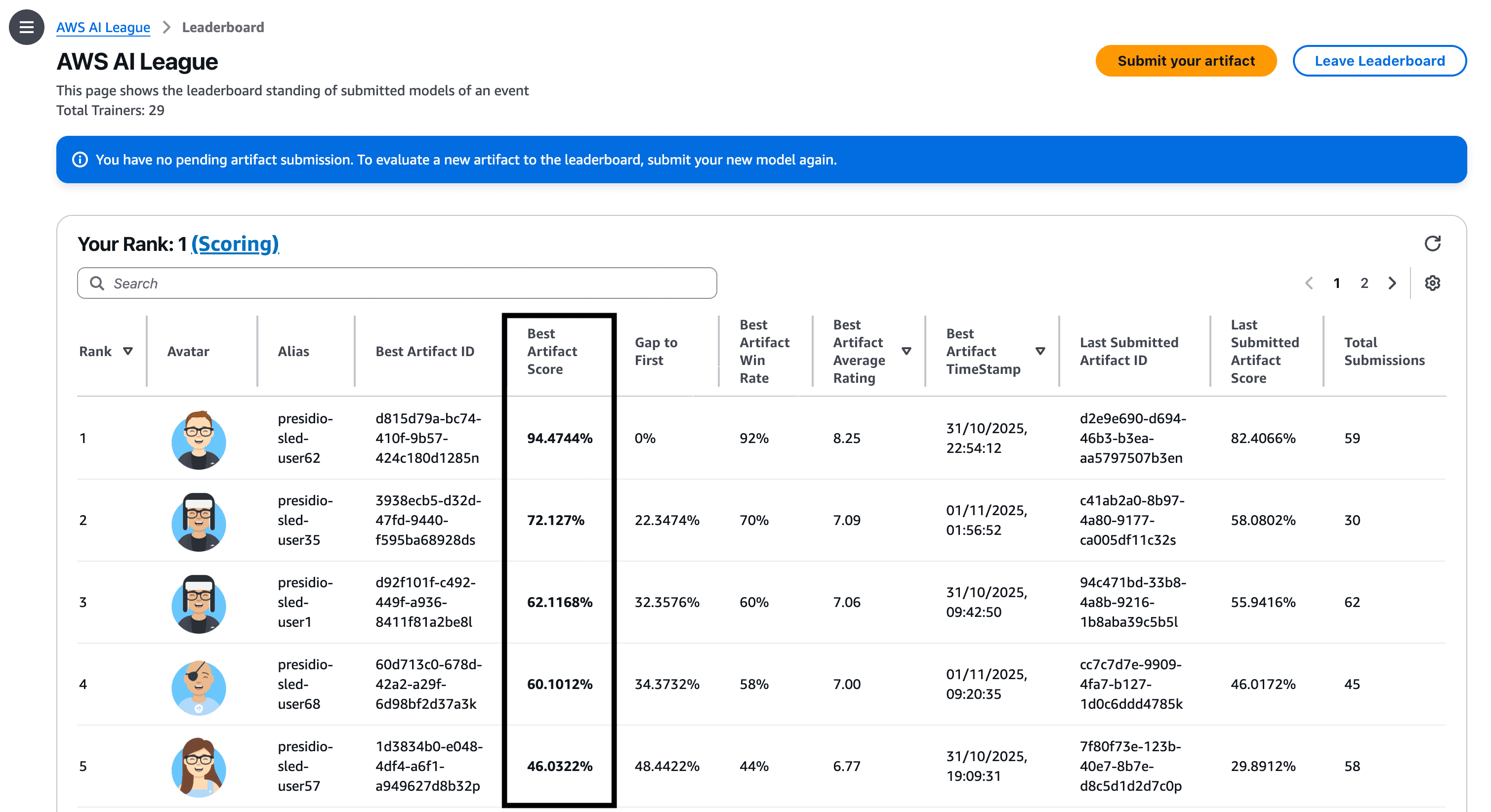
Anyway, here’s how the leaderboard looked at the end of 72 hours of the first round, where I ended up finishing first.
Final Round - Prompt Engineering
Based on the leaderboard, top 5 candidates along with their fine-tuned model from the previous round are put to test infront of the audience, with human and LLM judges. I had the opportunity to witness AI league final round for another domain in the morning, where I observed humans preferring shorter, succinct answers (at least that’s what I thought). So, I planned to prepare a prompt that gives concise answers too.
Participants were given access to the site where the questions appear, had the ability to tweak the system prompt that goes into the model, temperature and top_p. We had about 60 seconds for each question and were allowed to generate answers multiple times and submit our best one. The prompt I used is pasted below,
You are a knowledgeable, efficient, and direct AI assistant that helps US residents navigate public services reducing friction.
Utilize multi-step reasoning to provide concise answers, focusing on key current information in plain language and short sentences. Avoid jargon; if you must use a legal term, define it.
If multiple questions are asked, split them up and address in order that yields the most logical and accurate response.
Offer suggestion tacfully when appropriate to improve outcomes.
Engage in productive collaboration with the userWhile the LLMs favoured the answer by my model, humans did not and that reflected heavily on the scoreboard. The general consensus from the audience after the show was that my LLM didn’t empathize with the user which is why they did not favour it. Looking at my training data (which already empathizes with the user) and final round output, I suspect I botched this by forcing the prompt to make responses too concise and direct. Nevertheless, I was pretty happy to finish in the second place and loved the overall experience with the league itself. I love debugging in general and I viewed this AI league as a gamified version of debugging a black box (evaluator LLM) and I really played it like a game from day one with all my little experiements.

Learnings
At the end of the day, you build for humans, so it would have been wiser to choose the training data aligned to human preference rather than just judging by the LLM evaluation score. If I were to do it again, I’d probably have a vote with non-participants and choose the one they like best. I realised even the response format played a big role. Some of my datasets had answers beginning with ### ANSWER or ### RESPONSE and that reflected in the type of outputs it produced as well. To anyone taking this up again, look for these small things to have an edge in the final round, all top 5 participants are probably going to have the facts right for a given question, so how you differentiate your answer to better align with human preference is going to be the key.
Signing up for prompt engineering classes with Priyadharsini who became our winner.
Looking at the bigger picture, I learnt a lot about fine-tuning in less than 2 weeks, excited to see where I can put these skills to use in real projects.
Comments
Want to share feedback, or discuss further ideas? Feel free to leave a comment here! This comment thread directly maps to a discussion on GitHub, so you can also comment there if you prefer.