One evening, I was asked to validate the technical feasibility of automatically generating lyrical video for a given song. Unfortunately this time, I only had a couple of days to do it. The input being the song itself(mp3/wav) and the lyrics as a .txt file. The goal was to produce a video with lyrics in the foreground and video in the background. There was one additional constraint: use only services/models in AWS or that can be hosted on AWS.
Given the time constraint and the goal of just ensuring feasibility, I decided to get the end-to-end flow working before thinking about improving the quality of the output.
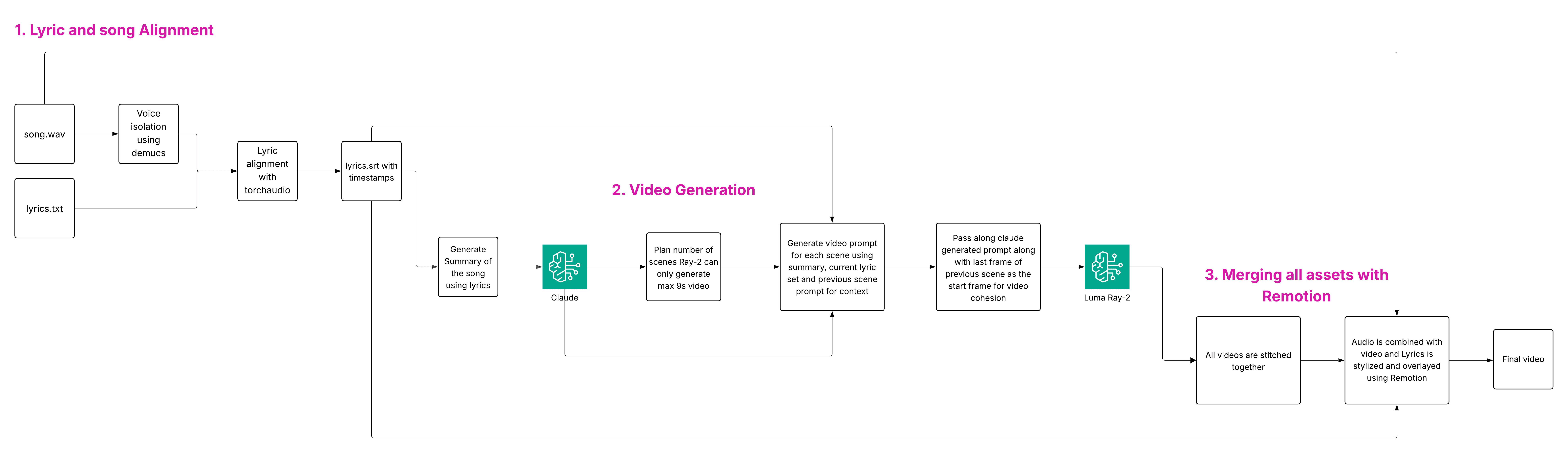
First things first, I broke this down into subproblems:
- How to generate the video?
- How to sync/align the lyrics to the song?
- Once the video is generated, how do we overlay/merge the lyrics and audio in the video?
How to generate the video?
I found a couple of models in AWS that were readily available and capable of generating videos from a text prompt, Nova Reel, and Luma AI’s Ray2 on Amazon Bedrock. Given the time constraints, instead of agonizing over which was better, I tested Ray2 first. It was able to follow instructions, but it had its limitations—for example, it could only generate 5 or 9 second clips. So, for generating a video for an entire song, one would have to split it up into scenes for generation and stitch it back together. (Later learnt that Nova Reel has a multi-shot mode that generates up to ~2-minute videos as a sequence of 6-second shots with per-shot prompts)
But how do we maintain scene cohesion? How can one ensure adjacent scenes don’t feel like two unrelated videos stitched together?
Luckily, the model also allowed you to specify the start or end image of the generated video. I took advantage of this and made sure the adjacent scene always used the last frame from the previous scene as the starting point.
At this point, I manually prompted and generated a couple of scenes and saw that the model was able to produce cohesive outputs, then moved on to the next puzzle.
How to sync/align the lyrics to the song?
The easiest way to achieve this would have been to transcribe the given song, since it would give us a subtitle(srt) file which we could use to sync song and the lyrics. But I already had the lyrics, which meant I didn’t necessarily need to transcribe. Even transcribing speech isn’t 100% perfect, so one can’t expect that for a song with all the “oohs” and “aahs” likely in it. A quick Google search showed what I needed was technically called forced alignment i.e. given the lyrics, match the lyric to the audio and get timestamps for (each line of) the lyrics and ultimately produce a subtitle file that can be easily merged with the video.
For this, I explored a few tools. A quick summary:
- Aeneas — Couldn’t get it working on macOS.
- WhisperX — Promised word‑level accuracy; but transcribes by default and required additional work to only run forced alignment.
- Torchaudio — Closest results so far; roughly ~60% of lines were correctly timed
As you can see, none of these methods yielded good-enough results. Before entirely discarding them, I tried isolating the vocals from the song, hoping for better alignment. Experimented with a couple of tools then landed on, Demucs: A deep-learning–based music source separation model that can split a mix into stems like vocals, drums, etc. This produced clean vocal isolation, you can compare the original and the vocal isolated version below,
I was able to obtain pretty accurate (~98%) results by performing forced alignment on the voice isolated version.
How to overlay/merge the lyrics along with audio in the video?
FFmpeg was the easiest option to combine video and audio and add lyrics as subtitles. But lyric videos usually have lyrics overlaid on top of the video, not just as a subtitle, and I wanted a way to programmatically style the lyrics depending on the mood of the song. That’s when Remotion came into the picture, you can use Remotion to style lyrics using just CSS, and it seemed like a perfect fit. For now, I looped the couple of scenes generated in the first step to fill the entire song, combined them with the subtitle file I had previously produced, and merged everything with Remotion. The results were pretty promising, and by this time I had already exhausted a day.
Generating the full-length video
Now that we had a flow in place, I went back to generating a full-length video. My first idea was to split up the lyrics into 9-second chunks and feed them into Claude to have it produce prompts that could depict the meaning of the lyrics on screen, which could then be fed into the video-gen model.
One thing this would lack is the overarching meaning of the song, since Claude would only see isolated portions of the lyrics. So, in addition to the lyrics, I first generated a summary of the song, then passed both the lyrics and the summary so the model had more context.
For generating consecutive scenes, I also passed in the prompt produced by Claude for the previous scene so it could cohesively continue the story with the overall theme of the song (remember we also pass the last frame of the previous scene to Ray2 to maintain scene cohesion). Sample clip and the scene-by-scene video-gen prompts for a song below:
SONG_SUMMARY: # "In The End" - Linkin Park The video tracks a journey through futile effort and inevitable loss, beginning with quiet resignation before building to emotional intensity and returning to acceptance. The energy rises from contemplative verses to powerful choruses, with a dramatic bridge that represents the final emotional breaking point. Visual motifs of clocks, pendulums, and things slipping away reinforce the central theme of wasted time and effort, while the nu-metal/rap-rock fusion reflects the early 2000s cultural moment when anger and vulnerability could coexist in mainstream music.
SCENE_ID: shot_005
I wasted it all just to watch you go I kept everything inside And even though I tried, it all fell apart What it meant to me will eventually be a memory of a time when
A figure kneels amid a crumbling room where walls disintegrate into swirling particles. Their outstretched hands try desperately to gather floating photographs and mementos that dissolve upon touch. The camera circles slowly, revealing the floor beneath them forming a spiraling vortex pulling everything downward. Rain continues streaming down invisible barriers as timepieces from the previous scene shatter in slow-motion. Muted blues deepen to midnight indigos with amber light pulses intensifying at 105 BPM. The camera occasionally jolts with quick cuts of the figure's face showing resignation as their surroundings—their memories—collapse into nothingness.
SCENE_ID: shot_006
I tried so hard and got so far But in the end, it doesn't even matter
A solitary figure stands atop a mountain summit at dusk, arms outstretched in triumph, silhouetted against a dramatic sky of deep indigos and amber streaks. As the camera pulls back, revealing the arduous path climbed, the mountain begins crumbling beneath them. The summit dissolves into particles that spiral upward while timepieces embedded in the rock face tick backward. The figure reaches desperately for a distant light that recedes despite their efforts. Camera movement alternates between steady pans and jarring handheld shots at 105 BPM as the entire landscape transforms into a collapsing hourglass formation, with the figure sliding down amid the ruins of their achievement.
SCENE_ID: shot_007
I had to fall to lose it all
The figure plummets through darkness, their body rotating in slow motion as fragments of their achievement—glowing amber particles and broken clock faces—spiral around them. The camera tracks their descent through layers of indigo mist, occasionally flashing to close-ups of their resigned expression. As they impact an obsidian surface, it shatters like black glass, revealing a vast underground landscape of submerged ruins and toppled monuments. Their silhouette dissolves into rippling reflections across dark water, each wavelet carrying away pieces of identity. The lighting transitions from harsh spotlights to diffuse blue shadows as everything of value disintegrates into the depths at a rhythmic 105 BPM pulse.
SCENE_ID: shot_008
But in the end, it doesn't even matter One thing, I don't know why It doesn't even matter how hard you try
A solitary figure stands before a massive hourglass, its sand nearly depleted, casting long shadows across a desolate landscape of eroded monuments. As they push against the immovable glass with increasing desperation, their reflection multiplies across fractured surfaces, each version trying different approaches but achieving nothing. The camera slowly pulls back through layers of translucent barriers, revealing countless parallel attempts all ending in failure. Amber particles from previous efforts rain down, briefly illuminating the scene before fading to indigo darkness. The hourglass finally empties completely as the figure's silhouette dissolves into the same obsidian surface from before, their determination rendered meaningless against cosmic indifference. Lighting pulses between warm determination and cold reality at 105 BPM.
SCENE_ID: shot_009
Keep that in mind, I designed this rhyme to remind myself how I tried so hard In spite of the way you were mockin' me Actin' like I was part of your property Rememberin' all the times you fought with me
A figure frantically writes glowing words in the air that shatter and fall as ash, surrounded by towering walls of handwritten journals that begin to collapse inward. Their shadow splits into two silhouettes—one mocking, one desperate—circling each other in a tense dance as property deed papers swirl around them. Memories materialize as floating polaroids that ignite at the edges, their smoke forming confrontational faces. The camera tracks backward through a corridor of closing doors, each slamming with increasing force matching the 105 BPM. The amber particles from before crystallize into chains that the figure struggles against, their determination creating brief flares of crimson light against the persistent indigo darkness.
SCENE_ID: shot_010
I'm surprised it got so far Things aren't the way they were before You wouldn't even recognize me anymore
A figure stands before a mirror that fractures into countless shards, each reflecting a different version of their former self. As they reach toward their reflection, their hand passes through, disturbing the surface like water. The environment morphs from familiar to alien—a childhood bedroom warping into an unrecognizable landscape of twisted architecture and desaturated colors. Photographs on walls age rapidly, faces becoming unidentifiable. The camera slowly circles as the figure tries to reconstruct memories from the floating ash of burned polaroids, but the particles slip through their fingers. Indigo shadows lengthen while amber light dims, matching the 105 BPM rhythm of realization and loss.The results were good enough to show that it’s technically feasible. The end-to-end workflow below,
The generation adapted well to the mood of the song: the colors and motion matched the theme, quoting one instance in a different song, when the lyric said “current in the ocean” the scene actually showed a current in the ocean with fish swimming in it. Surely, there was a lot of room for improvement, but the overall result gave me the confidence to say we can tackle it.
Looking ahead, what can be improved?
Moving into the next phase, I would happily reuse the lyric-alignment portion of this feasibility test, look for more performant alternatives to Remotion that provide the same flexibility, and spend the bulk of my time on video generation—learning storytelling, crafting prompts, and fine-tuning that workflow. A few things that particularly can be improved:
- The current set of generated videos, although they match the mood and the lyrics to an extent, weren’t really telling a story. So, the first course of action would be to prepare a storyboard for the song and scenes and make sure it collectively conveys a coherent narrative and provide flexibility to the users to refine individual scenes.
- Even integrate a character animation / replacement model like Wan2.2 Animate for the end users to enact as a chosen character for a particular scene, if they desire so
- Explicitly prompt the model to avoid any motion that breaks real-world physics
- Pass in cultural nuances, theme, and other metadata of the song can be provided alongside the summary to produce a more meaningful video
- Include beat and tempo information from the song so that the video matches it better
- Expressive words: animate specific words (“fall”, “rise”, “fade”) with matching motion presets
- Lyric-aware layout: break lines where the singer breathes to avoid widows/orphans
- Look for more cost effective models
In addition, researched some open source tools built for this purpose; that’s when I found promising AI editors such as, ComfyUI and Gausian Native Editor (keeping an eye on this AI movie hackathon results to see what we can learn from the participants), passed all of this on to the team handling the next phase of the project. I’m excited to see what they are able to achieve.
Comments
Want to share feedback, or discuss further ideas? Feel free to leave a comment here! This comment thread directly maps to a discussion on GitHub, so you can also comment there if you prefer.